
Many of us like to think that we’re free to go wherever we want – at least while we’re still young and without too many commitments. In reality, however, there are lots of routines each of us follow from day to day, like the following pattern: home -> work -> lunch -> work, and so on. But how much do we actually stick to these routines and how strongly do they dictate our daily lives? Could we try to build a mathematical model to capture the routines and quantify how predictable our movements are?
Well, the answer is – obviously – yes we can (what could we not try to model mathematically?). And indeed, this is exactly what I did for my master’s thesis back in 2012 when I was doing an internship at Idiap, Switzerland.
Next, I’m going to describe the data we used, tell something about the model, and finally present the results and some discussion. If you don’t care about the technical details, you can jump directly to the results section. If you do actually care about the details, you’ll probably want to read our paper 😉
Data
In order to do the modeling, we need some data against which we can test the predictions of our models. I’m not sure how widely people are aware of it, but most of us are already producing this type of data by allowing our smartphones with various apps collect GPS data. For my thesis project, I got the place visit sequences of 80 (anonymized) persons who had participated in a data collection campaign for about a year carrying along a smartphone given to them.
Model
There are of course many factors affecting our decisions about where to go next but it turned out that we can make pretty accurate predictions already based on two variables: the current time and the current place of a person. If it’s 8 A.M. on a Monday morning and you’re at home, you’ll probably head out to work or school next. And when at work, you’re likely to go for a lunch if it’s noon but after a few hours have passed, your home or maybe the city center become more and more probable next destinations. So each place has its own characteristic time distribution describing when people typically visit the place. Below you can see some time distributions for different place categories computed based on Foursquare data.

Check-in time distributions at different Foursquare venue categories.
 In slightly more technical terms, the model I used was probabilistic and essentially based on a product of a Markov model (capturing spatial patterns) and a time distribution like those above. I also studied the so called cold start problem which occurs if the person has collected the data only for a short period of time meaning that we cannot yet infer the distributions accurately. I showed that in this case, we can improve the predictions by taking an external dataset collected from an unrelated set of people in order to learn some general temporal patterns we might expect to observe for any place.
In slightly more technical terms, the model I used was probabilistic and essentially based on a product of a Markov model (capturing spatial patterns) and a time distribution like those above. I also studied the so called cold start problem which occurs if the person has collected the data only for a short period of time meaning that we cannot yet infer the distributions accurately. I showed that in this case, we can improve the predictions by taking an external dataset collected from an unrelated set of people in order to learn some general temporal patterns we might expect to observe for any place.
Last Friday, I presented this work at the Machine Learning “Summer” School in Iceland (the picture on the right) from where I’m also writing this post.
Results
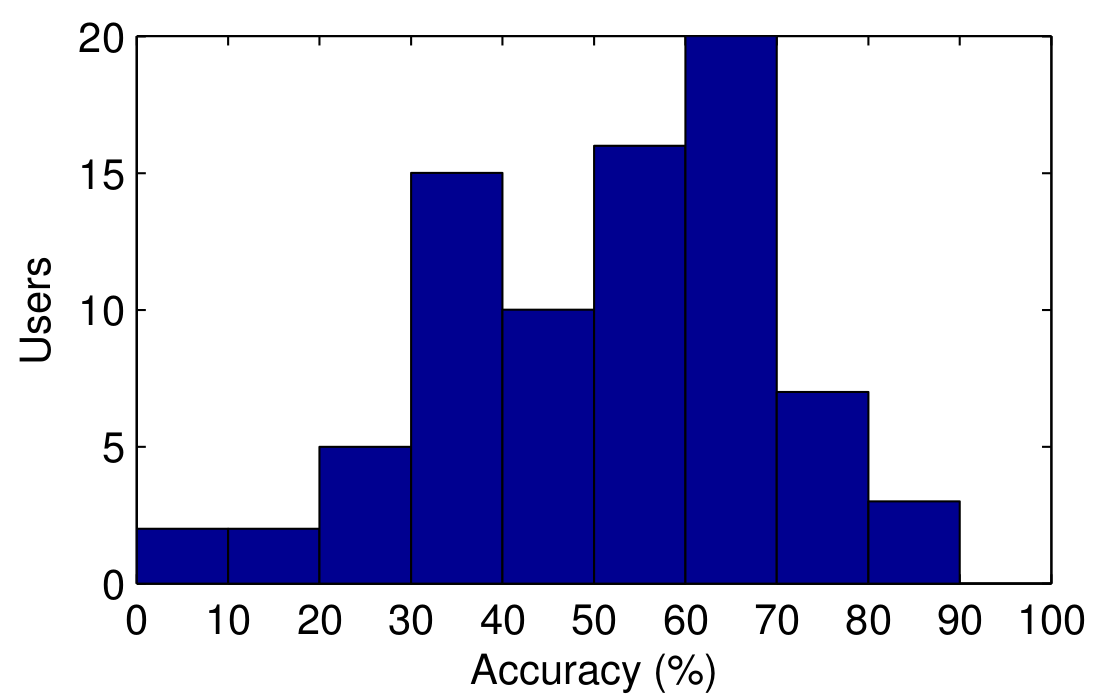
When I got my first results, I was quite surprised to learn how predictable people are. On average we could predict the next place of a person with 53 % accuracy. This is pretty good given that the average number of different places per person was 51 so if you were to throw your 51-sided dice, you could have expected an accuracy of only about 2 %. Quite interestingly, the predictability varied a lot from person to person. Below you can see the distribution of the accuracies we obtained for different people. While some people were very hard to predict, there was one individual whose next place the model was able to predict with an 86 % accuracy!
But why?
When I tell people about this project, almost always I get asked why do you want to predict where people will go next; what can you use it for, apart from some objectionable “big brother” applications. Well, I think that one could actually build some useful applications based on this type of modeling. For instance, Google Maps could automatically show you the nearest and best rated restaurants, if it predicts that you’re going for a dinner next, or Spotify could automatically customize your playlist to suit your mood depending on whether you’re heading to work or just about to start your holiday. One might of course call these “objectionable big brother applications”, but I think there’s a trade-off between privacy and utility you get from your smartphone.
In any case, the reason why I originally got interested in this problem was not the applications but because I think the question about the predictability of human mobility is very interesting in itself. Most of us have the intuitive notion that we have some sort of a free will on matters like where do I want to go next. But as it turns out, quite often we seem to choose our next place rather deterministically – maybe even most of the time as the above experiments suggest! So the interesting question is not whether we can predict human mobility but to what extent can we predict it. By adding some extra variables, like where your friends are currently at, we could surely increase the prediction accuracy above 53 %. But how much exactly can we push it? At some point, will we hit a barrier after which we simply cannot improve the accuracy anymore? A barrier that one might call free will, aleatoric uncertainty, or perhaps something totally different.
References:
- Malmi, Eric. Human Mobility Prediction: A Probabilistic Transfer Learning Approach. Master’s thesis, Aalto University, 2013. (PDF)
- Malmi, Eric, Do, Trinh-Minh-Tri, Gatica-Perez, Daniel. Checking In or Checked In: Comparing Large-Scale Manual and Automatic Location Disclosure Patterns. In Proc. 11th Int. Conf. on Mobile and Ubiquitous Multimedia (MUM 2012), Ulm, Germany, 2012. (PDF) Best Paper Award Nomination
- Malmi, Eric, Do, Trinh-Minh-Tri, Gatica-Perez, Daniel. From Foursquare to my Square: Learning Check-in Behavior from Multiple Sources. In Proc. 7th Int. AAAI Conf. on Weblogs and Social Media (ICWSM 2013), Boston, U.S., 2013. (PDF)

Nice post Eric, do you maybe have an Ipython notebook of the same with the model people can play with?
LikeLike
Thanks Billy! Unfortunately, it’s done in Matlab and the data is not publicly available but you need to request an access to it separately. However, I’m moving more and more towards using Python maybe the next model.. 🙂
LikeLike
An excellent post, Eric, thank you. It was good to meet you in Reykjavik. When we talked at your poster, I had the impression that you used an automatic process to cluster the venue categories, did I understand correctly? Do any of your publications detail this?
LikeLike
Hi Isabel! Yes, you’re right, the figure in the post is done based on Foursquare categories but I also did the same thing unsupervisedly using a mixture model. This has been described in my master’s thesis (link above) in Sec. 6.2, Sec. 6.4.1, and Fig. 6.6, in particular. Hope you’ll find it useful!
LikeLike
thank you Eric
LikeLike